���ں�
���ں�̽�֣������û���Ϊ�����ݼ���
2014-03-14 10:33:57
- +1 ������
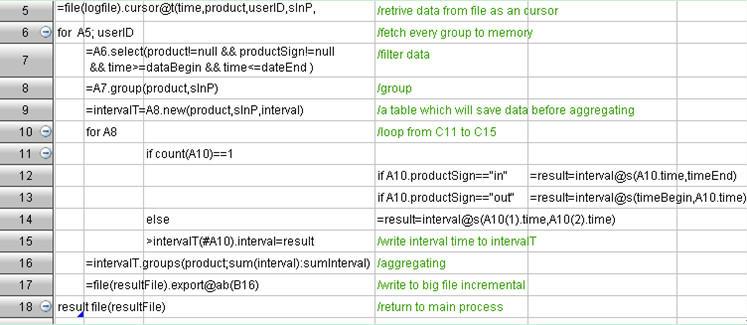
�û���Ϊ�����ݵ��ص������û������Ӵ�ÿ���û�����Ϊ������С������û���Ϊ�ļ����Ϊ���ӣ��û�֮��Ĺ���������Խ��١�
�û������Ӵ�ͨ����¼�еĵ绰���롢������־�е��û���š��˻���Ϣ�е������˻�������¼�й�Ʊ�˻���������Ϣ�еı������ˣ���Щ�����û���Ϊ�������е��û����û�������ͨ�������Ӵ�Ŀɴ��ڼ�����࣬�ٵ�Ҳ�а���

ÿ���û�����Ϊ������С��������Ӵ���û�������ÿ���û�����Ϊͨ�����١��Ե����绰������˵��ƽ��ÿ�µ�ͨ����¼ֻ����������ÿ��Ҳ������һ��������ʹ����վ�Ļ�Ծ�û�������ÿ�����Ҳֻ�ܲ����ϰ�����Ϊ��¼��ÿ�겻����ʮ������
�û���Ϊ�ļ����Ϊ���ӡ������û������ε�¼��������������������Ʒ���ۻ�����ʱ�䣬��Щ��������û���Ϊ�ļ��㣬ͨ������һ���ĸ����ԡ�
�û�֮��Ĺ���������١��û�����Ϊ��Զ�����һ�㲻��Ҫ֪�������û�����ʵ�ּ��㡣��Ӧ�ģ��û�֮��Ĺ�����������٣����磺ij��ͨ����¼�н����绰��һ����ͨ��ʱ��;�罻��վ��ij���û������ѹ�������Щ��Ʒ����Щ������ڵ����ࡣ
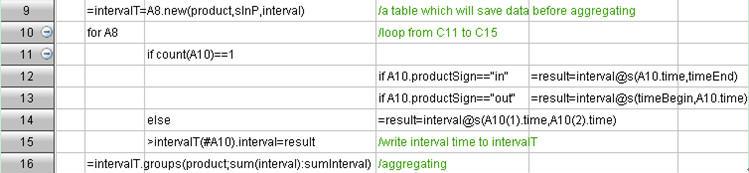
�����û���Ϊ������ݵ��ص㲻�ѿ���������ֱ��������д�����㷨����������ƣ�ÿ�ν�ijһ�û�����������һ���Լ��ص��ڴ��������㣬����Ҫ��������Ӳ����ȡij���û��IJ������ݣ�Ҳ��Ҫ�������û�������ͬʱ���ص��ڴ��С�
��ijһ�û����������ݼ��ص��ڴ��������㡣����������Ϊ�û�֮��Ĺ��������٣��������û���Ϊ�ļ����Ϊ���ӣ�����ͬһ���û������ݿ����ó���Ա���ٲ�������ݵĸ��š��������ij�û������������Ʒ�����ȣ���ij�û������ݰ���Ʒ������ܳ�ÿ����Ʒ�Ĺ������;�ٰ�������������;���˵�ֻ������һ�ε���Ʒ��ʣ�µľ��Ƿ����������Ʒ������������ٱ������ij�û����ۻ�����ʱ�������û�����ʶ�Σ�ÿ�ζ����γ�һ�Ե�¼���˳��������Ҫ���˳����еĵ�¼���˳���¼;�����ÿһ�η��ʣ����˳�ʱ�̼�ȥ��¼ʱ�̣�����ǵ���ʱ��;���������ʱ����ӣ������ۻ�ʱ����
���⣬��Ϊÿ���û�����Ϊ������Խ��٣���ȫ����ȫ�����ؽ��ڴ�����������ļ��㡣
��Ҫ��������Ӳ�̶�ȡ�û��IJ������ݡ������û�����Ϊ����Ƚϸ��ӣ�ͬһ���û��ĸ�������֮���Ǵ��ڹ�����ϵ�ģ���ȡһ���û��IJ��ּ�¼ȥ����ᵼ���㷨��д���������ܺܵ͡�
��Ҫ�������û�������ͬʱ���ص��ڴ��С������û������Ӵ���Ȼ�����ܽ�ȫ���û�������һ���Լ��ص��ڴ�����������Ҫ������ȡ�������ı������Ѿ����������ˣ����û������������û�֮��������ĺϲ��������������һ�������������û�֮����������٣�����ϲ��dz���������������û������������Ʒ���ۼ�����ʱ����ֻҪ�����ÿ���û������������Ʒ���ۼƵ�����ʱ�����ٽ������û��ļ������ϲ��Ϳ��ԡ�������Կ������������û�֮��Ĺ����٣���˴����㷨���ʺ�ʹ�ò��м��㣬��ÿ���ڵ������һ���������û��������Ȳ��������Ѷ����ܴ��������ܡ�
��ͬһ�û����������ݼ��ص��ڴ��������㣬�����Ҫ���Ƚ����ݰ��û��ֳɶ���顣���簴���۵��Ա���飬ÿ�������ij����Ա��Ӧ�Ķ����ɹ���¼;���û���ŷ֣�ÿ������ij���û���Ӧ����ҳ���ʼ�¼�������ʵ�������������ݰ��û�����ʹͬһ���û������ݰ���һ�𡣿����������ڼ����û���ÿ�û������������Ǹ��dz������Ĺ��̡�����������Լ��ٷ���Ĺ��̡�
���������Ȱ��û�����ͬ�ļ���Ŀ�궼ʹ��ͬ������õ����ݡ��������ʱ�仨��ǰ�����ֻ��һ�Σ���Ϳ��Ա������ʱ�Ĵ���������ͬ��ͬһ������Ŀ��Ҳ�����ظ�����������ظ�����ͬ�ļ���Ŀ�껹����ʡȥ��ͬ��������̡�
���ǣ����ҵ��ǣ�һ��ļ��㹤������ʵ�������㷨������Ч����������������ݡ�����SQL(��Hive)��MapRreduce��
SQL�����ѡ�SQL�ļ���������ģ����Ȱ��������²����ź���������������ܱ��Ż�����ȷ�Ż������кܴ��żȻ�ԣ�����֤��ѯʱ�����źõĴ����ѯ����Ҫ�����ݡ�
Hive����SQL������ͬʱҲ֧�ֲ��м��㣬����ȴ�����ʺ��û���Ϊ������ݼ��㡣������Ϊ�û���Ϊ�ļ����Ϊ���ӣ���Ҫ���ں��������洢�������������Hiveֻ֧�ֻ�����SQL�����֧�ִ��ں����ʹ洢���̡�
�û���Ϊ�ļ���֮���Խ�Ϊ���ӣ�����Ϊ��Ҫ��ͬһ���û��Ķ�������֮����м��㣬���ּ������˳����ء�SQL����������֧�����ޣ�ֻ�д��ں�������ʵ�ֲ��ּ�������㣬�����ڸ��ӵ�ҵ������Ȼ�Ե÷dz����������Ҿ�����Ϊ��������ɵ��µ����ܡ�ʹ�ó����ԵĴ洢���̱�д���Ӵ������ʵ�ָ��ӵ�������㣬�����Ѹ���SQL�ļ����������������д������дӻ��������Լ���д������������ͨ����SQL���͡�
MapReduce�����ѡ�MapReduce֧�ִ����ݲ��м��㣬ͬʱ�����ó����Ե�JAVA��������д�ģ���һ��ʹ洢�����������ԡ����ǣ�MapReduce��ʹ�õ� JAVA����ȱ����Խṹ���ݼ������⣬���еĵײ㹦�ܶ�Ҫ�Լ�ʵ�֣����顢����ѯ�������ȵȣ��������������ϸ��ӵ��㷨��Ҫ��д�Ĵ�����ࡢ��д�Ѷȸ���ά���������ѡ�ͬ���ģ�MapReduceҲ�������Ѿ�����õ����ݣ���shuffle�λ���Ҫ����������
SQL��MapReduce��������������õ����ݣ����Ը����ܵؽ�ͬһ�û����������ݼ��ص��ڴ��������㣬�û�������ݼ�����˻��������ܡ���չ�ԺͿ����Ѷȵ���ս��
���������������õ����ݣ��Դ˼�����д�ѶȲ���������ܣ�
��������֧�ֶ�ڵ㲢�м���ij���������ԣ����ṩ�ḻ��������㡣������������ź�������֧��ͨ���α��������ȡ���ݣ�ÿ�ζ�ȡһ�����ݽ��ڴ棬���ⷴ���������ʣ���������ֻҪ����һ�μ��ɣ��Ӷ�ʹ���ܴ����ߡ�������ڼ��㸴�ӣ������������걸�����������ݼ�����⣬��������ʵ�ָ��ิ�ӵ�������㡣��
������֧��������ɵĶ�ڵ㲢�м��㣬���Խ�һ���Ż����ܡ�����֮һ���û���ij�ַ�ʽ�ֶΣ��Դ�ʵ�ֲַ��洢��ĸ�Ч���д��������罫��Ա�������ݰ��ջ�Ա��ŵ�ǰ��λ�ֳ�100�δ洢��HDFS��ÿ�δ洢ʮ���Ա��һ�������ݡ����߽���վ��־�����û�ID������ĸ����ݷֶΣ�ÿ�δ洢�������û������ݡ����߽�ͨ����¼�������ź��û������ϲ�Ϊ30�Σ�ÿ�δ洢һ���ݻ��ݵ��û��������ֶδ�����ÿ�����ݶ����ź���ģ��ɱ��ڵ����һ���̶߳��������������IJ��м������ܸ��ߡ�
���������ѵ㣬�����á�ÿ���û���ÿ�ֲ�Ʒ�ϵ��ۻ�����ʱ�䡱Ϊ����˵����������һ�����취��
���������ѣ������������ݣ��Թ����ּ���Ŀ��ʹ�á��ڽڵ������ʱ����ֱ�Ӱ��û�����ȡ������Ч�����Ѿ������������������ܡ�

���ڼ��㸴�ӣ�esProc�����걸�����������ݼ�����⣬��������ʵ�ָ��ิ�ӵ�������㡣
�����Ĵ������£�
ԭ�����ӣ�//www.36dsj.com/archives/6812
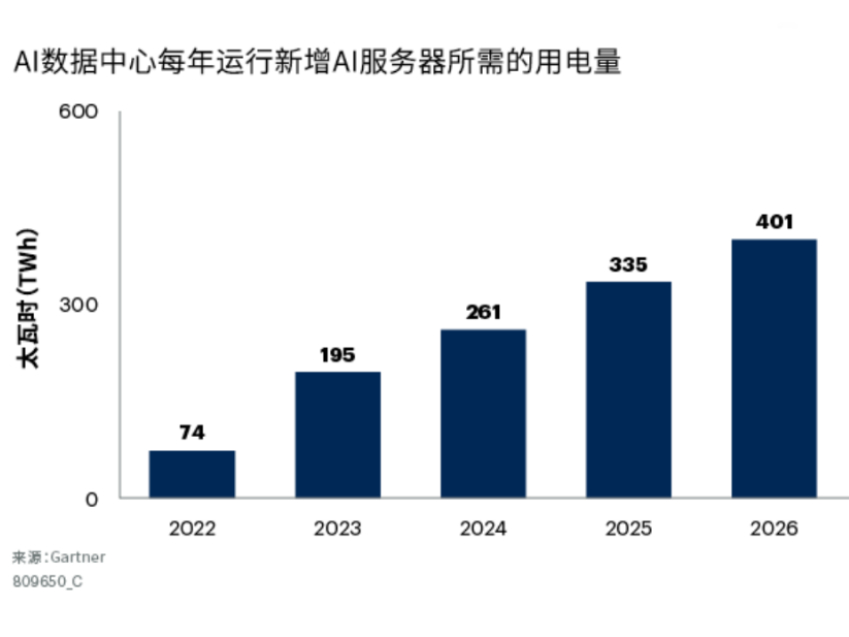


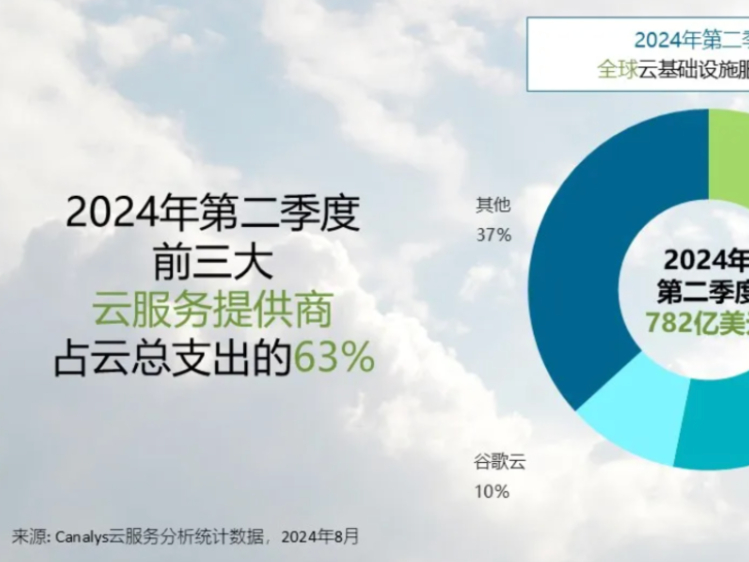


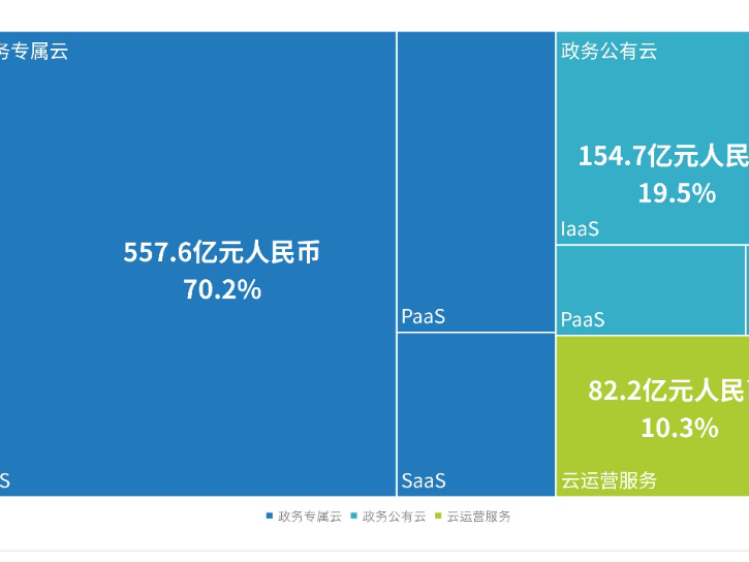

LinkinPark 36������
������Ѷ
������Ƶ
��Ʒ����
 X
X

 ����֤��¼
����֤��¼
 QQ�˺ŵ�¼
QQ�˺ŵ�¼
 ���˺ŵ�¼
���˺ŵ�¼