公众号
公众号40系显卡只是虚招 企业级产品才是英伟达GTC大会潜在主角
2022-09-22 09:36:37
- +1 你赞过了
【雷竞技须安全稳定 企业频道】当地时间9月20日,英伟达在GTC 2022技术大会上,终于推出了备受期待的RTX 40系列显卡,相信今晨大家也已经被这条消息刷屏了,我们再次就不多赘述了,这次,我们要说的是,在同场发布会上,英伟达在图形计算架构、游戏开发、AI 加速、工业元宇宙、云计算、量子计算等方面的新产品、技术以及最新进展。

黄仁勋在线上演讲中表示:“在加速计算和AI的推动下,计算正在以惊人的速度发展。加速计算的非凡愿景开启了AI的进步,而AI反过来又将触及全球各个行业,新想法、新产品和新应用因此涌现。”
英伟达H100投产
黄仁勋再次将系统和软件与广泛的技术趋势联系到一起,他表示大型语言模型(LLM)和推荐系统是当今最重要的两种AI模型。
他表示,推荐系统“掌管着数字经济”,推动着从电子商务到娱乐再到广告的一切发展。“它们是社交媒体、数字广告、电子商务和搜索背后的引擎。”
大型语言模型如今是AI研究最活跃的领域之一,它基于2017年首次推出的Transformer 深度学习模型而建立,能够在没有监督或标记数据集的情况下学习理解人类语言。
黄仁勋表示:“一个预训练模型可以执行多种任务,如问题回答、文件摘要、文本生成、翻译,甚至软件编程。”
他表示英伟达H100 Tensor Core GPU以及Hopper的新一代Transformer Engine已经全面投产,将在未来几周陆续发货。它们正在为这些巨大模型提供所需的计算能力。

H100 GPU今年3月份的GTC大会上发布,距今刚好半年了,采用Hopper架构,GH100大核心,台积电4nm制造工艺、CoWoS 2.5D封装技术,集成800亿个晶体管,核心面积814平方毫米。
它拥有18432个CUDA核心、576个Tensor核心、60MB二级缓存,支持6144-bit位宽的六颗HBM3/HBM2e,支持PCIe 5.0,支持第四代NVLink总线。
H100计算卡有SXM、PCIe 5.0两种样式,其中SXM版本15872个CUDA核心、528个Tensor核心, PCIe 5.0版本14952个CUDA核心、456个Tensor核心,功耗最高达700W。
黄仁勋表示:“H100很快就会被用于助力全球的AI工厂。”
L40 GPU全面投产
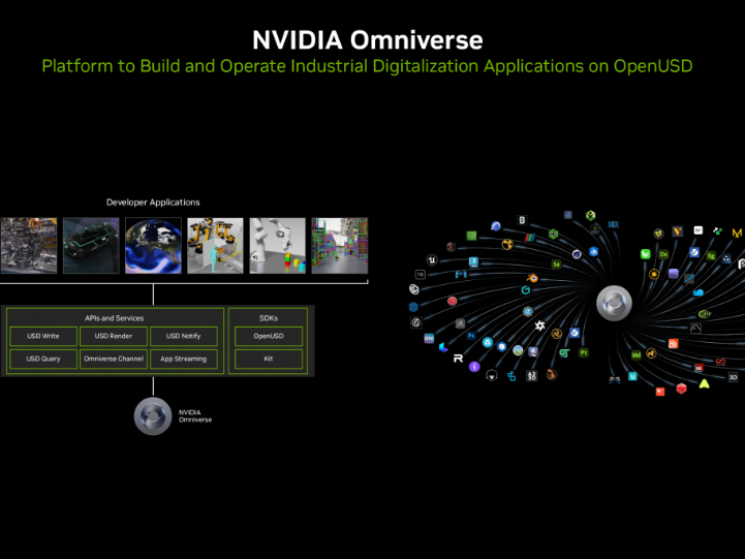
黄仁勋表示:“互联网的下一次进化,即元宇宙将通过3D技术扩展。Omniverse是英伟达用于构建和运行元宇宙应用的平台。”
英伟达认为,互联网的下一次进化,即元宇宙将通过3D技术扩展。面向元宇宙应用,英伟达宣布推出专为扩展元宇宙应用而打造的第二代OVX服务器,由全新Ada Lovelace L40数据中心GPU和增强的网络技术提供支持,以提供突破性的实时图形、AI和数字孪生模拟功能。Omniverse是英伟达用于构建和运行元宇宙应用的平台。
连接和模拟这个世界需要强大且灵活的新型计算机,黄仁勋解释了其中的奥义。英伟达 OVX服务器就是专为扩展元宇宙应用而打造的。
黄仁勋宣布英伟达第二代OVX系统将由Ada Lovelace L40数据中心GPU提供支持,该GPU现已全面投产。
英伟达发布史上最强算力芯片
黄仁勋在GTC 2022的主旨演讲上正式宣布,英伟达将于2024年推出最新一代英伟达DRIVE SoC Thor,直接代替了原计划于2024年量产的Atlan。

Atlan算力为1000TOPS,已经是目前市场之最,而Thor则是直接将算力拉到了2000 TOPS,同时,浮点算力也达到2000 TFLOPS。
更让人惊叹的是,Thor既可以将其2000 TOPS和2000 FLOPS的算力全部用于自动驾驶工作流,也可配置为将一部分用于座舱AI和信息娱乐,一部分用于辅助驾驶。
也就是说,Thor既可以用作单独的自动驾驶芯片,也可以用作驾舱融合芯片,同时满足自动驾驶和智能座舱所需的算力。
目前已经实现量产的自动驾驶和智能座舱芯片中性能最强大的分别是英伟达Orin和高通8155,前者算力256 TOPS,后者算力8 TOPS,浮点算力1000 GFLOPS,相当于英伟达用Thor一颗芯片就同时干掉了自家的Orin和高通的8155。
虚拟世界新服务
黄仁勋表示,大型语言模型“是当今最重要的AI模型”。基于Transformer架构,这些大型模型可以在没有监督和标记数据集的情况下学习理解意义或语言,解锁无与伦比的新能力。
为了帮助研究人员更轻松地将该技术应用到其工作中,英伟达在GTC大会上宣布推出英伟达 BioNeMo LLM服务和框架,以便制药公司、生物技术初创企业和前沿生物研究人员加速开发用于生成、预测和理解生物分子数据的AI应用。

英伟达BioNeMo框架用于训练和部署超算规模的大型生物分子语言模型,帮助科学家更好地了解疾病,并为患者找到治疗方法。该大型语言模型(LLM)框架将支持化学、蛋白质、DNA和RNA数据格式。除语言模型框架之外,英伟达BioNeMo还提供一项云API服务,该服务将支持越来越多的预训练AI模型。
以前,使用自然语言处理模型来处理生物数据的科学家一般会训练相对较小、需要自定义预处理的神经网络。而通过BioNeMo,科学家可将其扩展为具有数十亿参数的LLM,捕捉分子结构、蛋白质溶解度等信息。
英伟达BioNeMo是英伟达Clara Discovery药物研发框架、应用和AI模型集的一部分,可实现大规模自监督语言模型的GPU加速训练。这一针对特定领域的框架支持以SMILES化学结构标记表征的分子数据、以及以FASTA氨基酸和核酸序列字符串表征的分子数据,使基于生物分子数据的大规模神经网络训练更为轻松。
借助该框架,科学家能够使用更大的数据集来训练大规模语言模型,打造出性能更强大的神经网络。
黄仁勋还详细介绍了英伟达Omniverse Cloud。这项基础设施即服务(IaaS)可以连接在云端、本地或设备上运行的Omniverse应用。
黄仁勋宣布,新的Omniverse容器现已可以部署到云端,该容器包括用于合成数据生成的Replicator、用于扩展渲染农场的Farm以及用于构建和训练AI机器人的IsaacSim。
Omniverse正在被广泛采用,黄仁勋分享了几个客户故事与演示:拥有近2,000家零售店的Lowe’s正在使用Omniverse来设计、构建和运营门店的数字孪生;
市值500亿美元的电信运营商Charter和互动数据分析商HEAVY.AI正在使用Omniverse创建Charter 4G和5G网络的数字孪生。
通用汽车正在使用Omniverse来为他们的密歇根设计工作室创建数字孪生,设计师、工程师和营销人员可以在这个数字孪生中协同工作。
比上代快80倍的Jetson Orin Nano
机器人计算机“是一种最新的计算机类型”,能够将一切可移动的机器转移到虚拟世界。黄仁勋将英伟达第二代机器人处理器Orin描述为一次重要的成功。

为了将Orin带到更多的市场,黄仁勋宣布推出Jetson Orin Nano。这款微型机器人计算机比上一代备受欢迎的Jetson Nano快80倍。
JetsonOrin Nano可运行英伟达Isaac机器人堆栈并采用ROS 2 GPU加速框架。英伟达Isaac Sim机器人模拟平台现已在云端可用。
对于使用AWSRoboMaker的机器人开发者,黄仁勋宣布,用于英伟达 Isaac机器人开发平台的容器已在亚马逊云科技商店上架。
写在最后
正如历年来英伟达的产品发布会和技术峰会一般,本届GTC也是发布种类繁多、信息量巨大且密集。
我们发现,整场发布会重点讲述了英伟达Omniverse在元宇宙这一方面的强力作用。AI在自动驾驶领域等方面的应用等,核心内容是To B端的,从中我们也可以看到英伟达继续开阔B端市场的决心和信心。









最新资讯
热门视频
新品评测
 X
X

 微博认证登录
微博认证登录
 QQ账号登录
QQ账号登录
 微信账号登录
微信账号登录